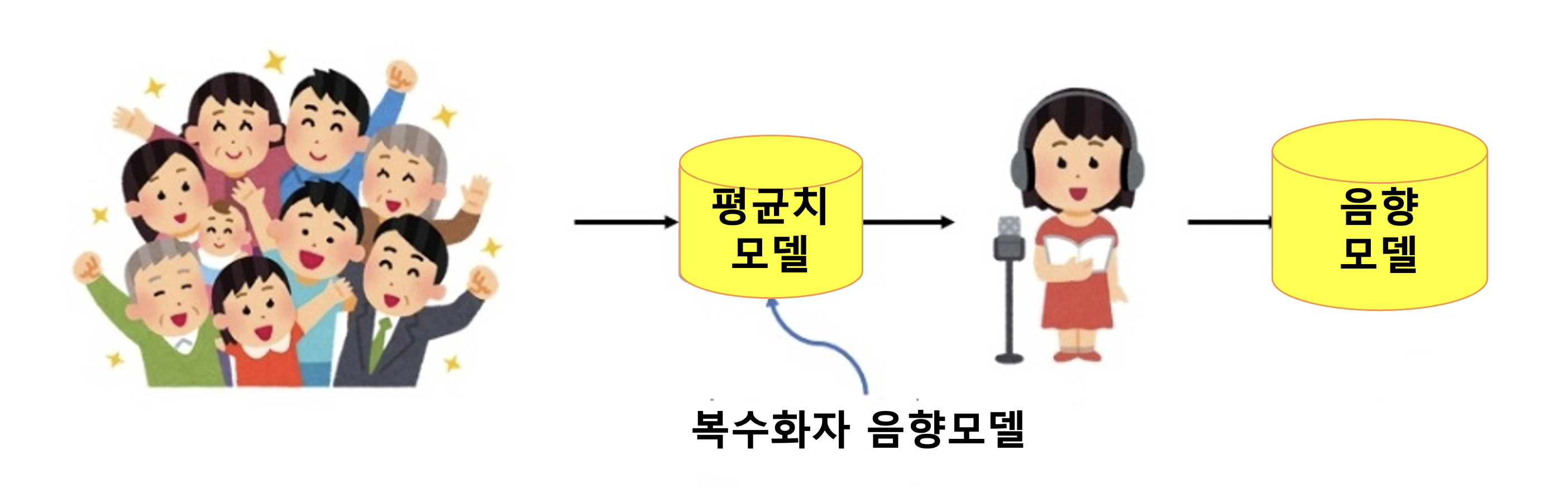
다중 화자(Multi-speaker) 모델
구조도
✓ 여러 화자의 음성을 조금씩 학습(각 2시간, 합계 40시간)하여 평균치 모델 구축
✓ 평균치 모델에 최종 화자의 소량 음성 (약 30분)을 학습하여 음향 모델 생성
✓ 단일 화자 모델 대비 (12시간 필요) 소량의 최종 화자의 음성(30분 필요)으로도 학습 가능